
During the OFM Forum last week, there were a few discussions around the relationship between the Human Workflow (WF_TASK*) tables in the SOA_INFRA schema and BPMN processes. It is important to know how these are related because it can have a performance impact. We have seen this performance issue several times when BPMN processes are used to model high volume system integrations without knowing all of the implications of using BPMN in this pattern.
Most people assume that BPMN instances and their related data are stored in the CUBE_*, DLV_*, and AUDIT_* tables in the same way that BPEL instances are stored, with additional data in the BPM_* tables as well. The group of tables that is not usually considered though is the WF* tables that are used for Human Workflow. The WFTASK table is used by all BPMN processes in order to support features such as process level comments and attachments, whether those features are currently used in the process or not.
For a standard human task that is created from a BPMN process, the following data is stored in the WFTASK table:
- One row per human task that is created
- The COMPONENTTYPE = “Workflow”
- TASKDEFINITIONID = Human Task ID (partition/CompositeName!Version/TaskName)
- ACCESSKEY = NULL
For a given BPMN process the following additional rows are stored in the WFTASK table:
One row per BPMN process instance with:
- COMPONENTYPE = “BPMN”
- TASKID = Instance ID (For example: 850002)
- TASKDEFINITIONID = partition/CompositeName!Version/ProcessName
- ACTIVITYNAME = Process Name
- A predefined title, which is seen as the title in the process tracking tab of the workspace
An additional row for each thread created within a BPMN instance which contains a callback. This would include the use of Inclusive gateways, Parallel gateways, Loop, and Multi Instance sub processes that contain human tasks, signals, message or receive events. These rows will look the same as original BPMN instance row, but the TASKID will also include a thread with the instance id such as 850002-1-0.
We will now look at an example process to see the implications of this on the number of rows in the WFTASK table. Below is the process model we will execute which contains:
- A message start event
- A parallel gateway with paths leading a message event and a human task
- A script activity
- A 2nd parallal gateway with 2 paths each leading to a human task
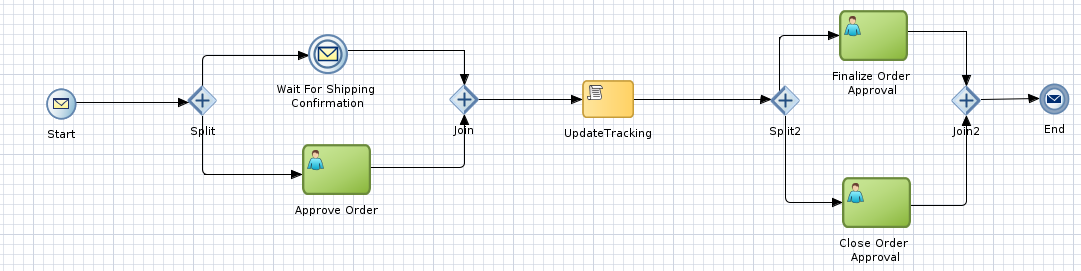
In this scenario, we would most likely expect to see a single row in the COMPOSITE_INSTANCE table as well as a single row in the CUBE_INSTANCE table. We would also expect 3 rows in the WFTASK table for the 3 Human Tasks that are executed as part of a our process. Our assumptions would be correct for the COMPOSITE_INSTANCE and CUBE_INSTANCE tables, but as we will see not the WFTASK table.
First, I have created an instance of this process using the message start event which created instance 850005. As the audit trail image shows, it is now waiting for a mid process receive and a human task to be completed.

If we look at the WFTASK table at this point, we will see four rows all related to instance id 850003.


The first row is for the human task, which is the expected row. We then see three additional rows with TASKID 850005-2-0, 850005-1-0 and 850005. These represent the process instance(850005) as well as the 2 copies within the split. You will see that 850005-2-0 has an ACCESSKEY of CATCH_INTERMEDIATE_EVENT which is for the “Wait for Shipping Confirmation” message and 850005-1-0 has an ACCESSKEY of USER_TASK for the “Approve Order” human task. Each of these is waiting for a callback which is why they also required a row in the WFTASK table. You can see that all three of these have BPMN as the component type and BpmFlexFieldProcess as the component name as well.
Now once the human task is completed and the message event is received we see the following results in the WFTASK table:


We now see the parent BPMN row is still in an OPEN state, but the other three original rows are now in a null state because they have completed. We also see four new rows created, two Workflow type rows and two BPMN type rows. These represent the two human tasks as well as the two new threads of the BPMN instance created from the second split.
As we can see, even in this simple case we have a total of eight rows in the WFTASK table when we only created three human tasks for users. In this scenario we have almost tripled the number of rows created, but this was still a relatively simple scenario. If there is an orchestration process in BPMN which processes a batch in either a loop or parallel and needed to invoke an asynchronous service within the processing of each time, the number of WFTASK rows could increase very quickly.
Although there may be many more rows in WFTASK than you might expect, in many scenarios this will not affect performance with proper tuning. For example, if the size of the WFTASK table begins to impact the performance of the BPM Workspace for end users you most likely need to look at indexing the flex field columns that are frequently used by their views.
However, in some scenarios this could produce significant additional overhead. In the example of the orchestration that is operating on a batch of items, it would make more sense to implement this processing in a BPEL process instead. With a BPEL process, it would not will not have the additional overhead of the BPMN process.